Integrated Internet Information Architecture
September 3, 1994
Chris Weider, Bunyip Information Systems, Inc.
Mitra, Pandora Systems Inc Karen Sollins, MIT
Introduction
We have been working on Information Architecture issues for a few years now, and have worked on protocol specifications and enhancements for a number of the current widely used Internet information systems. We believe that widely varying retrieval requirements, security requirements, search and support techniques, caching and charging requirements mean that a single system cannot be implemented which will satisfy every user's information needs. In addition, as more and more communities use the Internet to store their information and transport their communications, we will need to allow them to transition gracefully from their current methods to new methods which utilize the full power of the Net. We cannot require them to rewrite their data to deliver it over Internet information tools because in many cases they have already developed tools and protocols analogous to those in use on the Internet.; we must provide them with an information architecture which allows them to use tools with which they are comfortable while integrating them into the current information mesh.
Therefore, we have decided to focus our attention on an information model, and a generic functional model for an Internet information architecture, rather than attempt to either a) kludge an existing protocol to provide everything for everyone or b) design such a system from scratch, which would be a waste of time.
We have (along with Karen Sollins, Larry Masinter, Michael Mealling, and several others) been developing a generic functional model for such an architecture. It is still in the early stages of development, but is firmly based on what has been learned in the deployment of the current set of tools, and on the practical work that Karen has been doing in her Information Mesh project.
The approach
A brief overview of our approach is as follows: we start off with a basic object oriented information model, where an object is not exactly analogous to the existing notions of 'document', 'file', etc., but is slightly more generic. We have identified a number of functional 'modules' in the architecture which mediate interaction with the objects, these modules cover such functionality as retrieval, resource-discovery, URN->URL lookup, viewing, transformations, security and charging etc. We do not envision each module being realized in a single monolithic system; rather, we merely specify the functional and interface requirements for such a module. Theintention is that modules would be usable across different information systems, for example a charging module might be used by both gopher and WWW. Seperating out modules allows the seperate development of modules, and their integration into a wide variety of information systems. As in the current Internet White Pages work, we wish to allow many different approaches to be taken to the implementation of the functionality, subject only to the constraint that those protocols which implement parts of the architecture must be able to interoperate, through the common interfaces.
Suggested process
Our goal, if such an approach is adopted by the IAB workshop participants, is to fully articulate such an architecture, picking the appropriate modules, and then to define the functional and interface requirements of these modules. Since some modules are going to be local, whereas others will be accessed across the network we will then need to start building new protocols to its requirements, and determining how existing protocols realize such an architecture. We fully intend to work in the IETF tradition of using existing successful practice as a touchstone for the validity and usefulness of our work. If we can develop such an architecture, then we have a framework which will serve to tie together the resources on the Internet into a single system, no matter how large it grows or how long it lasts.A simple example
The diagram below, shows a model of the way a few modules might link together in a manner analogous to the functionality of a WWW browser searching a resource discovery service, and then retrieving a file, its only enhancement over the existing functionality is to look up the URN returned by the WAIS server, at a resolution service, before retrieving the document via Gopher. Should this be all that is needed, then little would be gained by our approach, as compared to minor enhancements to existing tools such as Mosaic.
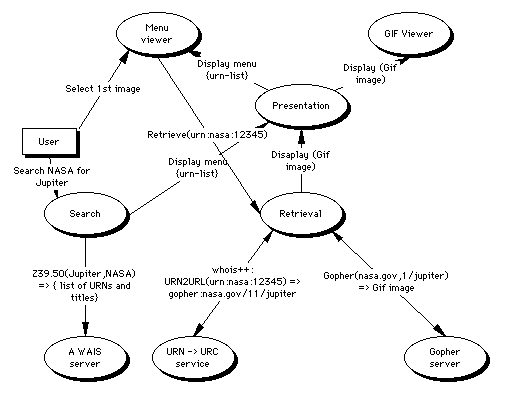
Complicating the issue
The value of modularity comes into play when we look at how to add all the extra functionality that is going to be desired. For example should someone design a caching module then the only part that needs changing in the diagram above should be the Retrieval module in order to take advantage of the new caching functionality.
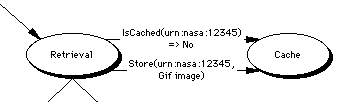
Modules
Our criteria for identifying a seperate module are that it should contain logically distinct functions. From a practical point of view the intention is that a developer should be able to build a module that conforms to the the functionality and interface described, and have that easily integrated by a client or server developer. As a first pass we have identified the following modules as being required. We welcome debate as to what modules are missing, or should be subdivided, and the functionality of those modules.
Retrieval
Gateways
URN resolution
Definitions server
Updates
Service location
Caching and replication
Security and Authentication
Payments, Charging and Accounting
Translation
Presentation
Searching and Indexing
Functionality
For each module we've attempted to define the functions required, again we encourage debate on these functions, at this stage there are obviously things that have been left out. The intention is to capture the generic concepts that each module handles internally, while obscuring things specific to any particular implementation of the module. This is not always easy and some relaxation of this principle might be needed in order to have a system that allows us to get the most out of any application.
The actual interface to these modules is likely to take several forms, for example some modules may be incorporated as libraries, linked into applications, others may be accessable over the network, in which case we will recommend a protocol below. In some cases, for example on Macintoshes, then some propriatrary method such as Apple Events, or RPCs may be used. It is hoped that this will have minimal effect on the actual modules.
In order to reduce the number of functions required below, two principles apply in all cases.
1) For any function, there needs to be the ability to ask for meta-information about that function, with a return value being the cost, estimated time, authentication etc. for that particular operation.
2) Most functions take a URI as an argument, this could be either a URN or a URL. In the case of a URN, the function may need to call a resolution module to obtain the URL.
Modules
Retrieval
This module manages retrieval of objects using protocols that are understood by this applicationIt is likely to call the following modules: Caching, URN resolution, Payments.
The only function we can currently envision for it is Retrieve(URI) -> Object.
Presentation
The presentation module, handles the display of an object to the user, it selects an appropriate viewer, if neccessary calling other modules to locate and or retrieve one.The only function it handles is:
Display(OBJECT, Parameters)
The functionality of the Presentation module will obviously have to be enhanced; this basic function assumes that the entire object has been retrieved onto a local machine; the use of firewalls and the existence of small data pipes may necessitate a negotiated fragment presentation scheme.
Searching
This module is used for database searching and resource discovery, very different techniques might be hidden under the same interface. It would handle the following functions.Search(URI to search, How to order, URC to search for) -> List of URI's
URN Resolution
A URN resolver is used to look up information about a URN or URL, returning a URC.The functions required are:
Resolve(URN, fields) -> URC, where fields specifies the meta-information to be returned. For example this might specify just to return a list of URLs.
Gateways
A gateway module typically runs in a server, where it accepts requests in one protocol, and then calls a Retrieve module that can speak the protocol required to actually fetch the object.The function defined for it is, as for the Retrieve module, Retrieve(URI)-> Object, however the call is going to arrive in some other protocol (e.g. gopher) in which the results will need returning.
Update Module
As the volume of material increases it becomes crucial to have consistency around objects and pointers to the metainformation. Hand edited URN->URC resolvers for example are going to get seriously out-of-date. This module allows the controlled update of material.Functions might be:
register(URN,URL) register that there is a new copy of a URN available
add(URL,OBJECT) create a new URL, with a particular body
delete(URN,URL) tell the URN2URC resolvers to forget about this URL
Definitions Server
This is a new concept, but fills in a gap where applications need to find out about new things, for example if an application sees a new Content-Type, it is going to want to find out what the content-type is, what viewers can handle it, where it might get a viewer for it. It replaces the functionality currently in hand-configured and distributed "config" files.Functions might be (this needs much more discussion and work).
Define(URL-prefix) -> Gateway
Define(Content-Type) -> List of viewers and translaters.
Service Location
This is used to find local or remote modules, for example find a URN2URC resolver.A typical function might be.
Locate(Service) -> URL of the service.
Although URL's may not be sufficient to describe a service's location.
There is a Service Location WG at the IETF, which will need liasing with, however initial discussions indicate that the Service Location Protocol will solve the problem of finding local resources, but not help to find remote resources since it is broadcast oriented. This is an example of where a single functional and interface definition might allow two very different internal systems to be accessed by the same applications.
Caching & Replication
This module, or modules will handle the process of cache management, simple modules might just make a copy of everything retrieved, while more complex modules might use sophisticated algorithms to manage the caches, decide what to replicate etc. In addition, the caching mechanism may also wish to partcipate in a cooperative distributed cache by announcing a local URL for the new copy of the resource. This would allow regions of the Net which have a large number of users behind a relatively thin pipe (Australia, for example) to use their user's machines as a local cache without having to decide what to retrieve. Such a function will also need a lot of support from the security and charging modules. The caching and replication server should support the following functions:Retrieve(URI,Fragment) -> OBJECT # return a cached, or remote copy of a file (keep a copy)
Store(URI,OBJECT) # Keep this object in case anyone else wants it
Tellmeabout(URI)->URI # Get more meta-information about a particular cached object
Security & Authentication
This module is going to be called by most of the other modules to authenticate actions requested. The interface will need to be able to handle different security models underneath, from ticket granting systems such as Kerberos, to public/private key based systems such as RSA or PGP.The interface for this should be at a high enough level to hide these differences, for example "give me a key" is not the kind of functionality we are looking for, that would be a function internal to the security module. Functions we might want could be.
AuthenticateAssertions(URC) -> Boolean # Checks the assertions (e.g. authorship) in a URC
IsThis(URL,URN) -> Boolean # Checks that a URL is really an example of a URN
SecureRetrieve(URI) -> Object # Obtains an object in a secure fashion
SignThis(URN,URL) # Creates a signature for a URL and stores it on a URN
Encrypt (OBJECT, Parameters) # Encrypt an object using some scheme
Payments, Charging & Accounting
As with security, it is neccessary to hide a variety of different schemes under a common interface. Payments system seem to come under two fairly different classes, either digital cash based - where a token that has value is passed around, or cheque based - where an IOU is passed around. The commonality of these can be expressed with the following functions.ObtainToken(Value) -> Token # Where the Token may be a cheque or cash
Pay(Token, Person) # Pay the token to the person
Cash(Token) # Handle a received token
Validate(Token) # Establish validity of a token, without changing it.
There is a second type of charging which may or may not need to happen at this layer; for example, the cost of retrieving the data (as opposed to paying for access to the data). In today's networks, retrieval costs are already built into the flat line charges, but that may not be the case in the future. In addition, we need an intelligent metric service which will determine which of a set of given URLs point to the 'closest' server.
Translation
In many cases, a desired resource may not be presentable on the current system because a) the necessary viewers have not been installed or b) the data type is not supported on the current system. Therefore, a client should be able to ask for a translation from a format it can not handle to one that it can. The function would look something like:Translate(object, inputformat, outputformat)
Protocol
We have deliberately not specified protocols above, the functionality and modularity of the interfaces should be independent of the method that modules use to inter-communicate, especially since much of the communication is likely to be within a single computer, where it makes lots of sense to use direct library calls or similar means to intercommunicate.However - it makes a lot of sense to specify a common protocol to be used between modules where they traverse a network.
Ideally it would make a lot of sense to be able to do this all on a single port, with a gatekeeper routing calls to appropriate modules that may or may not be seperate executables. This enables us to avoid using a dozen different ports for what might be a single program in some cases.
One approach to this would have been to use RPC, however unless we used DCE this would be vendor specific. Its also terrible to debug. The ideal protocol is going to allow the semantics of a function call, i.e. the ability to specify a function (or verb) and arguments. This rules out using variants of common protocols such as Gopher and Whois++ both of which are specialised for particular tasks. The best candidates would appear to be either Prospero or HTTP, both could be easily extended to handle additional verbs and objects.
Prospero's main advantage is its use of UDP (actually ARDP for reliability), this gives large performance improvements, especially for the kinds of small interactions many of these calls are going to be. In ARDP lack of a response can be caused by either a failure of the network, or a failure of the server, both of which are cause for retransmission
HTTP's advantage is that it is easy to debug via telnet, and easy to implement within existing frameworks.
This topic is a good one for further debate, whichever protocol is chosen we recommend a simple translation between the functional definitions, and the online protocol, so that simple extensions of functionality automatically define the way these functions are communicated over the wire. For example a Retrieval might be
RETRIEVE urn:path.net:mitra12345
in either Prospero or HTTP.